

K- Nearest Neighbor Algorithm:
- The most basic instance-based method is the K-Nearest Neighbor Learning.
- K-nearest neighbors (KNN) is a type of supervised learning algorithm can be used for both regression and classification. But mostly it is used for the Classification problems.
- K- nearest neighbors (KNN) is a non-parametric algorithm.
- This means that no assumptions about the dataset are made when the model is used. Rather, the model is constructed entirely from the provided data.
- This algorithm assumes all instances (data set) correspond to points in the n-dimensional space Rn.
- The nearest neighbors of an instance are calculated by using standard Euclidean distance.
How does the KNN algorithm work?
In K-nearest neighbors, K is the number of nearest neighbors. The number of neighbors is the core deciding factor. K is generally an odd number if the number of classes is 2. When K=1, then the algorithm is known as the nearest neighbor algorithm. This is the simplest case. Suppose P1 is the point, for which label needs to predict. First, you find the one closest point P1 and then the label of the nearest point assigned to P1.
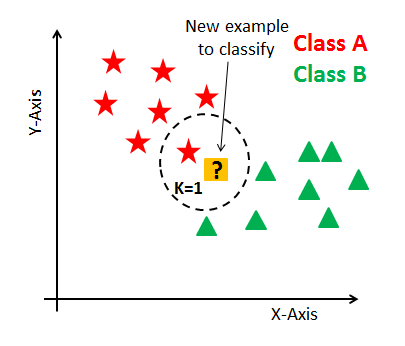
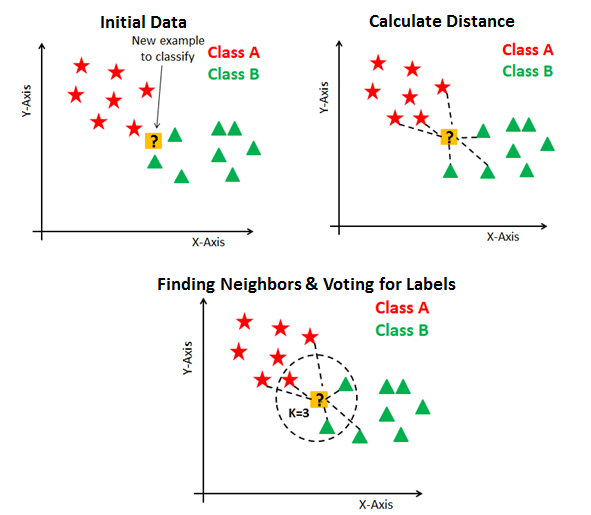
Suppose P1 is the point, for which label needs to predict. First, you find the k closest point to P1 and then classify points by majority vote of its k neighbors. Each object votes for their class and the class with the most votes is taken as the prediction. For finding closest similar points, you find the distance between points using distance measures such as Euclidean distance, Hamming distance, Manhattan distance and Minkowski distance. KNN has the following basic steps:
- Calculate distance
- Find closest neighbors
- Vote for labels
Eager Vs. Lazy Learners
Eager learners mean when given training points will construct a generalized model before performing prediction on given new points to classify. You can think of such learners as being ready, active and eager to classify unobserved data points.
Lazy Learning means there is no need for learning or training of the model. All of the data points used at the time of prediction. Lazy learners wait until the last minute before classifying any data point. Lazy learner stores merely the training dataset and waits until classification needs to perform. Only when it sees the test tuple does it perform generalization to classify the tuple based on its similarity to the stored training tuples. Unlike eager learning methods, lazy learners do less work in the training phase and more work in the testing phase to make a classification. Lazy learners are also known as instance-based learners because lazy learners store the training points or instances, and all learning is based on instances.

