


Introduction
Neural networks, that were actually inspired by the human brain’s neurons are a buzzword these days because of their ability to do an amazing amount of work in various domains.
Here I am not going to dive into the in-depth theory of neural networks, but for understanding the code some basic concepts will be explained.
For a deeper understanding, this article won’t be just enough, you have to go through some standard materials that are present.
Saying so, let me concisely explain some concepts. https://watch?v=bfmFfD2RIcg
Some Basic Concepts Related To Neural networks
Different Layers of a Neural Network
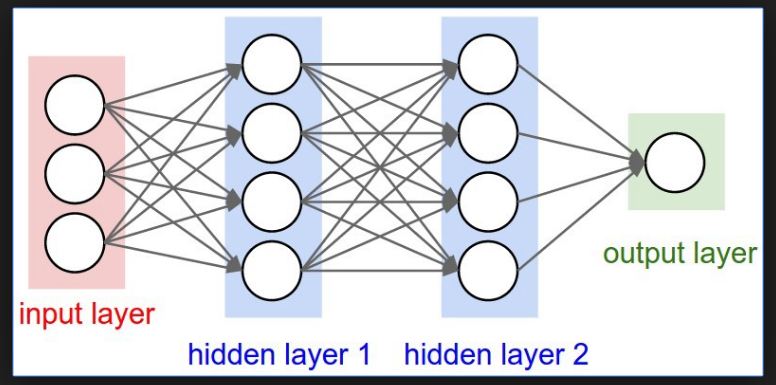
1.Input Layer – This is the gateway for the inputs that we feed.
2.Hidden layers – The layer where complex computations happen. The more your model has hidden layers, the more complex the model will be.
3.Output Layer
The number of nodes in the output layer basically depends upon the problem that we have taken.
2. Forward propagation
Keenly observe the above animation. This is a number classification problem and our input is the digit seven. During the forward propagation, we are pushing the input to the output layer through the hidden layers. Finally, we can observe that the model gave a higher probability/prediction that the input is number seven.
3.Backpropagation

The backpropagation algorithm has mainly two steps :
During the backward pass we calculate the derivative of the loss function at the output layer. Then we are applying the chain rule, to calculate the gradient of the weights present in the other layers. If you don’t know what weights and biases are please click here to get a better intuition.
Some simple optimization functions
the previous sections, a small intuition was provided about the gradient descent algorithm. But the normal gradient descent algorithm has a big disadvantage because it requires a huge amount of memory to load the entire dataset for computing the gradients.
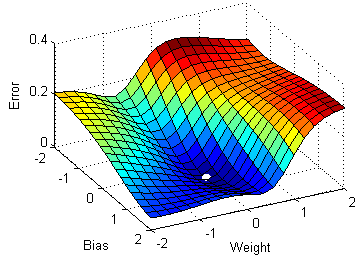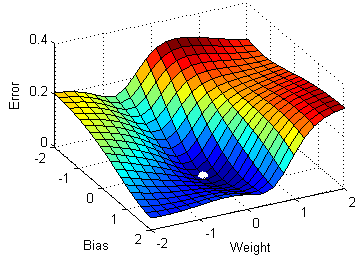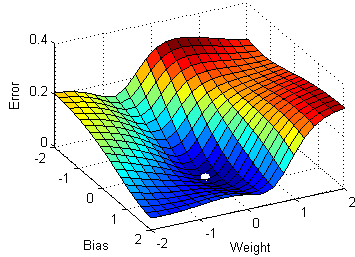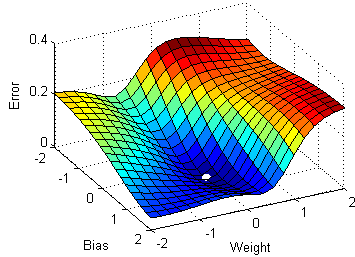
1.Stochastic Gradient Descent
Stochastic gradient descent a variant of the ordinary gradient descent algorithm computes the derivative of the parameters by considering one individual/training sample at a time instead of loading the whole of the dataset.



{kind=link}