


Hello Guys, today let’s discuss the topic “Secure Deep Reinforcement Learning”. Reinforcement learning is known as “a core technology for modern artificial intelligence”.
Deep Reinforcement Learning has emerged as an important family of techniques for training AI robots & agents. It has achieved human-level performance on Atari like complex games. However, at the same time, it is vulnerable also.
There are some of the examples where it overfit to the training environment. In this talk, There are adversarial examples in deep RL, which can harm humans as well. Hence, there is a framework for investigating generalization in deep RL towards building deep RL with greater resilience.
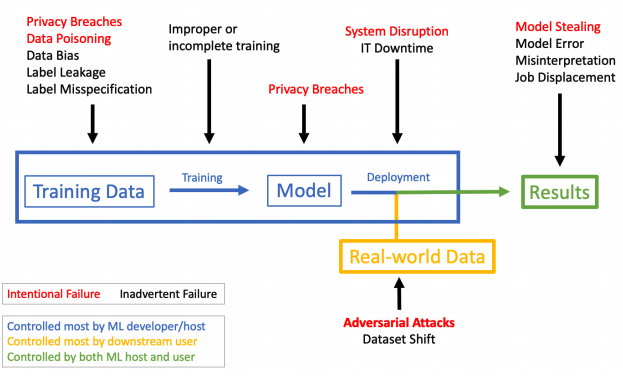
Measures for Secure Deep Reinforcement Learning
Since the inception of Deep Reinforcement Learning (DRL) algorithms, there has been an advancement in Artificial Intelligence. Both the research and the industrial communities are having an interest in this field. There are numerous applications of deep RL ranging from autonomous navigation applications and robotics to control applications in the infrastructure. It also has an influence on air traffic control, defense technologies, and cybersecurity.
The deep RL algorithms are tremendously increasing nowadays in industries and machineries. Hence, the security risks and issues in such algorithms are also increasing. It has been proved that DRL algorithms are having security risks. Hence, it needs to be taken care of.
Attack and defense in reinforcement learning
Various algorithms can be applied to some adversaries in order to manipulate the performance and behavior of DRL agents. Hence,to address such problems, one needs to aim to advance the current state of the art in different directions. Researchers need to address the problem of detecting replicated models by developing a novel technique for embedding sequential watermarks in DRL policies.
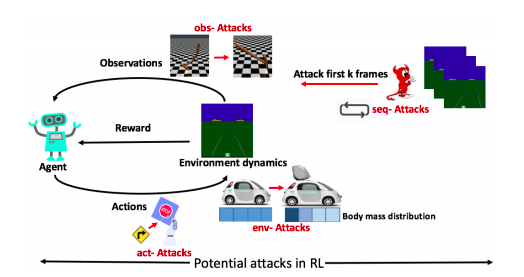
Adversarial attacks are classified into two categories :-
- Misclassification attacks: aiming for examples which can be misclassified by the target network.
- Targeted attacks: aiming for examples which can target misclassified into an arbitrary label.


{kind=link}